Data Warehouse Architecture
There are various ways in which a data warehouse can be
built and implemented. We will discuss about the following different
architectures with special reference to the first one:
- Generic Two-Level Architecture
- Independent Data Mart Model
- Dependent Data Mart Model and Operational Data Store
- Logical Data Mart and Active Data Warehouse
- Three Layer Architecture
All of these architectures involve some form of Extract, Transform and Load (ETL).
Generic Two Level Architecture

Source Data Systems:
Source data coming into the data warehouse may be
categorised into 4 broad categories:
Production Data:
i.
This category of data comes from the various
operational systems of the enterprise.
ii.
While dealing with this data, we come across
many variants of the data formats.
iii.
There is no conformance of the data among the
various operational systems of the enterprise. For example, a term like Account
may have different meanings in different systems.
iv.
Because of this data disparity, a greater
challenge is to standardise and transform the data from different operational
systems, convert the data and integrate the pieces into useful data for storage
in data warehouse.
Internal Data:
i.
This is the data internal to the organisation
and generally is in form of “private” spreadsheets, documents, customer
profiles and sometimes the departmental databases.
ii.
This add complexity to the process of
transforming and integrating the data in terms of determining the strategies
for collecting data from spreadsheets, finding ways of taking data from textual
documents.
iii.
Again we need to schedule the acquisition of
internal data. It is a collective judgement call on how much internal data
should be included in the data warehouse.
Archived Data:
i.
These are the old operational data which are
stored in archived files (in flat files on disk storage).
ii.
These are used for getting historical
information which is a major characteristics of data warehouse.
iii.
This type of data is useful for discerning patterns
and analysing trends.
External Data:
i.
These are the data from external sources
(sources outside of the organisation).
ii.
These are used to serve industry trends and
compare performance against other organisations.
iii.
These data don’t conform to our organisational
formats and hence we have to design conversions of the data into our internal
formats and data types.
iv.
We need to organise data transmissions from
external sources depending on when the data is received. In some cases, we may
get data on request.
Data Staging Area:
- After the data is extracted from various operational and external systems, we need to prepare the data for storing it in the data warehouse.
- Data staging component consists of workbench which provides the function of data extraction, transformation and preparation for loading to the data warehouse.
- This provides a place where the data is cleaned, changed, combined, converted, de-duplicated for use in the data warehouse.
Q: Why a Separate Staging Area?
A: Following are
the reasons/benefits of having a separate staging area in a data warehouse
implementation:
- Various Source Systems have different allotted timing for data extraction.
- Source systems are available for extraction during a specific time slot which is generally lesser than the overall data loading time. Hence it is good to have data in staging before we lose connection to the source system.
- We may need to extract data based on some conditions which requires us to join two or more different systems together. We will not be able to perform a SQL query joining two tables from two physically different databases.
- Data Warehouse’s data loading frequency doesn’t match with the refresh frequency of the source systems.
- Extracted data from the same set of source systems are going to be used in multiple places.
- ETL process involves more complex data transformation that require extra space to temporarily stage the data.
- There is specific data reconciliation/ debugging requirements which warrants the use of staging area for pre, during or post load data validations.
Data Storage Component:
-
Data storage for the data warehouse is a
separate repository. This is because:
o
Data repository for a data warehouse must
contain historical data for analysis which is not the case with the operational
systems.
o
Data should be in structures suitable for
analysis and not for quick retrieval of individual pieces of information.
o
Data in operational data base could change from
moment to moment. However analysts using the data from the data warehouse
require stable data which represents snapshots at specific periods. Hence data
warehouses are “read-only” repositories.

End-User Presentation Layer/Information Delivery Component:
- This is the layer where the data in the data warehouse is utilised by wide range of different users for analysis and reporting purpose.
- This layer involves different tools for presenting data to different users.

- Ad Hoc Reports are pre-defined reports primarily for novice and casual users.
- Provision for complex queries, Multi-Dimensional (MD) analysis and Statistical analysis cater to the needs of Business Analyst and Power Users.
- Executive Information System (EIS) is meant for senior-executives and high level managers.
- Data mining applications are knowledge discovery systems where the mining algorithm helps discover trends and pattern from the usage of the data.
Independent Data Mart Model
Data Mart à
These are mini-warehouses, limited in scope and pertains to specific line
of business.
Independent Data Mart à
A data mart filled with the data extracted from the operational environment
without the benefit of the data warehouse as these contain only the data from
the specific operational systems.
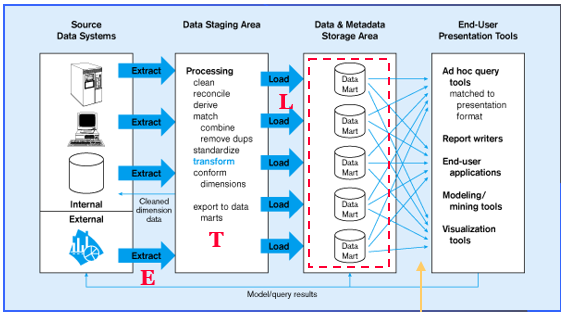
- Here there is separate ETL for Each Independent Data mart.
- Data Access complexity increases because of multiple data marts.
Dependent Data Mart Model With Operational Data Store
Dependent Data Mart à
These are filled exclusively from the enterprise data warehouse and its
reconciled data.
Operational Data Store
(ODS) à
Integrated, Subject Oriented, updatable, current-valued, enterprise-wide
and detailed database designed to serve operational users as they do decision
support processing.

- Here there is a single ETL for Enterprise Data Warehouse (EDW).
- Dependent Data arts loaded from EDW.
- ODS provides option for obtaining current data.
Logical Data Mart and Active Data Warehouse
Active Data Warehouse
à An EDW which has the
following features:
- Accepts near-real-time feed of the transactional data
- Records, analyses warehouse data and in near-real-time relays business rules to the data warehouse and systems of record so that immediate actions can be taken in response to business events.

- ETL here is near-real-time
- Data Marts are not separate databases and are logical views of the data warehouse.
Three Layer Architecture

- Reconciled Data: Detailed, current data intended to be the single, authoritative source for all decision support.
- Derived Data: Data that have been selected, formatted, and aggregated for end-user decision support application.
- Metadata: Technical and business data that describes the properties or characteristics of other data.
Introduction To DSS
- DSS stands for Decision Support System
- Data Warehouse plays a major role in decisions making of the organisations by making the historical data available for trend analysis.
- Basically there are two different types of decisions which are taken from different stages of the data warehouse which are below:
o
Tactical
Decisions: These decisions are taken for the day to day functioning of the
organisations. These are generally derived from the Operational Data Store
(ODS).
o
Strategic
Decisions: These decisions are taken for the long run. These decisions are
derived from analysing the data in the data warehouse for trends and also are
affected by the analysis of the external data. These are generally derived from
the Data Warehouse/Data marts.
Awesome blog i like to share few more information about ETL Testing Training
ReplyDeleteETL Testing Online Training
Thanks for Sharing a Very Informative Post & I read Your Article & I must say that is very helpful post for us.
ReplyDeleteData Science
Python
Selenium
ETL Testing
AWS
Thanks for sharing this. Here are a few links for (ETL testing / software testing) job seekers,
ReplyDeleteETL Testing Jobs
Job Portal For Software Testers